篇首语:本文由编程笔记#小编为大家整理,主要介绍了ELM预测基于matlab探路者算法优化极限学习机预测(含前后对比)含Matlab源码2204期相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了ELM预测基于matlab探路者算法优化极限学习机预测(含前后对比)含Matlab源码 2204期相关的知识,希望对你有一定的参考价值。
一、探路者算法简介
提出的一种新兴的智能优化算法,该算法的思想起源于群体动物的狩猎行为,种群中的个体分为探路者和跟随者两种角色。算法的寻优过程模拟了种群寻找食物的探索过程,利用探路者、跟随者两种角色不同的位置更新方式以及角色间的交流来实现优化,种群三代间的优良信息在迭代过程中也保留下来,能够快速获得较好的解。在种群更新中,探路者是整个种群位置的先行探索者,比跟随者先移动,探路者的位置更新公式为

基本探路者算法的步骤为
1)初始化系统参数。
2)初始化种群,计算出种群中个体的适应度值,适应度最优的个体成为探路者,其他个体是跟随者。
3)使用公式(4)对探路者位置进行更新。
4)使用公式(5)对跟随者位置进行更新。
5)计算种群中所有个体的适应度值,计算出全局最优解,并重新确定探路者和跟随者。
6)判断是否符合结束条件,符合就输出全局最优解,否则回到步骤3。
探路者算法具有便于理解、算法简单、优化性能良好等优点,探路者算法及其改进算法被已用于多个应用领域。利用混合探路者算法求解有限缓冲区和带能耗阈值约束的绿色流水车间调度问题,获得了良好的改进效果。针对医疗影像处理问题,提出一种基于探路者智能搜索算法,该算法能提高图像识别的效率和准确率。利用改进的探路者算法和样本熵进一步优化集成学习模型,利用优化模型预测PM2.5的浓度,实验表明,优化模型在稳健度和预测准确度都高于其他基准模型。将探路者算法用于软件预测缺陷模型,利用探路者算法优化神经网络的权重值,提高了软件预测缺陷的准确率。利用维度学习策略改进了探路者算法求解函数优化问题,对越界和迭代不成功个体采取了加强维度学习的策略,测试表明,改进的算法优于其他对比算法。由于探路者算法提出时间不长,应用领域还不够广泛,还没有被用于求解0-1背包问题。
二、部分源代码
%% 初始化
clear
close all
clc
format shortg
warning off
addpath(‘func_defined’)
%% 读取读取
data=xlsread(‘数据.xlsx’,‘Sheet1’,‘A1:N252’); %%使用xlsread函数读取EXCEL中对应范围的数据即可
%输入输出数据
input=data(:,1:end-1); %data的第一列-倒数第二列为特征指标
output=data(:,end); %data的最后面一列为输出的指标值
N=length(output); %全部样本数目
testNum=15; %设定测试样本数目
trainNum=N-testNum; %计算训练样本数目
%% 划分训练集、测试集
input_train = input(1:trainNum,:)‘;
output_train =output(1:trainNum)’;
input_test =input(trainNum+1:trainNum+testNum,:)‘;
output_test =output(trainNum+1:trainNum+testNum)’;
%% 数据归一化
[inputn,inputps]=mapminmax(input_train,-1,1);
[outputn,outputps]=mapminmax(output_train);
inputn_test=mapminmax(‘apply’,input_test,inputps);
%% 获取输入层节点、输出层节点个数
inputnum=size(input,2);
outputnum=size(output,2);
disp(‘/’)
disp(‘极限学习机ELM结构…’)
disp([‘输入层的节点数为:’,num2str(inputnum)])
disp([‘输出层的节点数为:’,num2str(outputnum)])
disp(’ ')
disp(‘隐含层节点的确定过程…’)
%确定隐含层节点个数
%注意:BP神经网络确定隐含层节点的方法是:采用经验公式hiddennum=sqrt(m+n)+a,m为输入层节点个数,n为输出层节点个数,a一般取为1-10之间的整数
%在极限学习机中,该经验公式往往会失效,设置较大的范围进行隐含层节点数目的确定即可。
MSE=1e+5; %初始化最小误差
for hiddennum=20:30
%用训练数据训练极限学习机模型
[IW0,B0,LW0,TF,TYPE] = elmtrain(inputn,outputn,hiddennum);
%对训练集仿真
an0=elmpredict(inputn,IW0,B0,LW0,TF,TYPE); %仿真结果
mse0=mse(outputn,an0); %仿真的均方误差
disp(['隐含层节点数为',num2str(hiddennum),'时,训练集的均方误差为:',num2str(mse0)])
%更新最佳的隐含层节点
if mse0 MSE=mse0;
hiddennum_best=hiddennum;
end
end
disp([‘最佳的隐含层节点数为:’,num2str(hiddennum_best),‘,相应的均方误差为:’,num2str(MSE)])
%% 训练最佳隐含层节点的极限学习机模型
disp(’ ')
disp(‘ELM极限学习机:’)
[IW0,B0,LW0,TF,TYPE] = elmtrain(inputn,outputn,hiddennum_best);
%% 模型测试
an0=elmpredict(inputn_test,IW0,B0,LW0,TF,TYPE); %用训练好的模型进行仿真
test_simu0=mapminmax(‘reverse’,an0,outputps); % 预测结果反归一化
%误差指标
[mae0,mse0,rmse0,mape0,error0,errorPercent0]=calc_error(output_test,test_simu0);
%% 麻雀搜索算法寻最优权值阈值
disp(’ ')
disp(‘SSA优化ELM极限学习机:’)
%初始化SSA参数
N=30; %初始种群规模
M=100; %最大进化代数
dim=inputnumhiddennum_best+hiddennum_best; %自变量个数
%自变量下限
lb=[-ones(1,inputnumhiddennum_best) … %输入层到隐含层的连接权值范围是[-1 1] 下限为-1
zeros(1,hiddennum_best)]; %隐含层阈值范围是[0 1] 下限为0
%自变量上限
ub=ones(1,dim);
[Convergence_curve,bestX]=PFA(N, dim, ub, lb,M,hiddennum_best, inputn, outputn, output_train, inputn_test ,outputps, output_test);
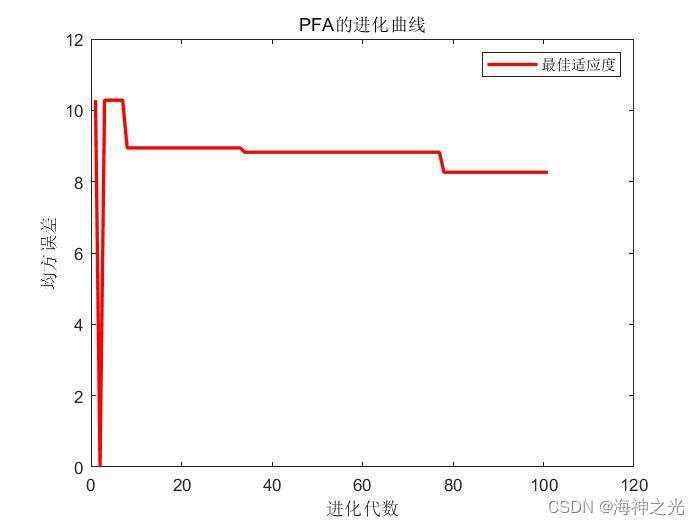
%% 绘制进化曲线
figure
plot(Convergence_curve,‘r-’,‘linewidth’,2)
xlabel(‘进化代数’)
ylabel(‘均方误差’)
legend(‘最佳适应度’)
title(‘PFA的进化曲线’)
%% 优化后的参数训练ELM极限学习机模型
[IW1,B1,LW1,TF,TYPE] = elmtrain(inputn,outputn,hiddennum_best,bestX ); %IW1 B1 LW1为优化后的ELM求得的训练参数
hiddennum_best
%% 优化后的ELM模型测试
an1=elmpredict(inputn_test,IW1,B1,LW1,TF,TYPE);
test_simu1=mapminmax(‘reverse’,an1,outputps);
%误差指标
[mae1,mse1,rmse1,mape1,error1,errorPercent1]=calc_error(output_test,test_simu1);
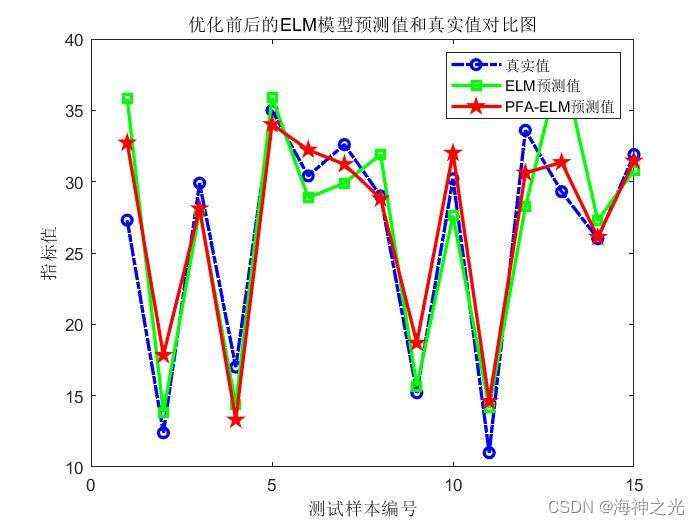
%% 作图
figure
plot(output_test,‘b-.o’,‘linewidth’,2)
hold on
plot(test_simu0,‘g-s’,‘linewidth’,2)
hold on
plot(test_simu1,‘r-p’,‘linewidth’,2)
legend(‘真实值’,‘ELM预测值’,‘PFA-ELM预测值’)
xlabel(‘测试样本编号’)
ylabel(‘指标值’)
title(‘优化前后的ELM模型预测值和真实值对比图’)
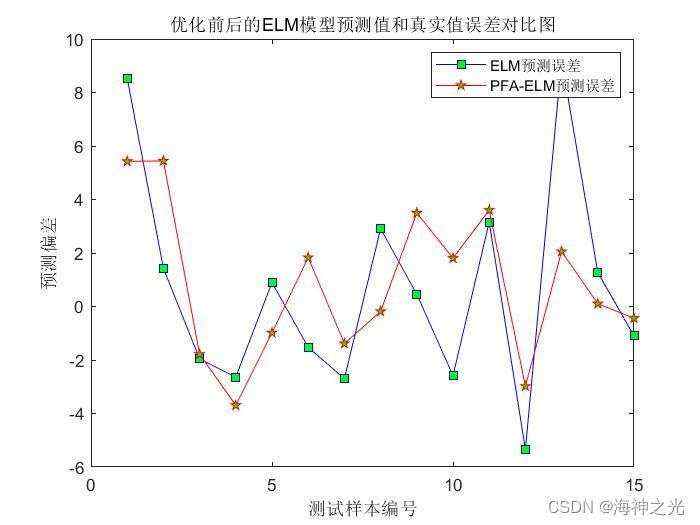
figure
plot(error0,‘b-s’,‘markerfacecolor’,‘g’)
hold on
plot(error1,‘r-p’,‘markerfacecolor’,‘g’)
legend(‘ELM预测误差’,‘PFA-ELM预测误差’)
xlabel(‘测试样本编号’)
ylabel(‘预测偏差’)
title(‘优化前后的ELM模型预测值和真实值误差对比图’)
三、运行结果
四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]张小萍,谭欢.基于改进探路者算法求解0-1背包问题[J].邵阳学院学报(自然科学版). 2022,19(01)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除




![[echarts] 同指标对比柱状图相关的知识介绍及应用示例](https://img7.php1.cn/3cdc5/c7bc/ae9/d860963d11bbd36d.jpeg)






 京公网安备 11010802041100号
京公网安备 11010802041100号